JavaScript 字符串反转乱码
前一段写了篇文章:JavaScript 8种字符串反转的方法 – 码农真经,介绍了js中反转字符串的几个方法,但有些字符串或有些方法无法达到预期结果,如:
emoji字符

"Trump 💩".split("").reverse().join("");
// "�� pmurT"

生僻汉字

"𠮷野家".split("").reverse().join("");
// "家野��"

复合字符
"noël".split("").reverse().join("");
//"l̈eon"

字符逆转虽然没有出现乱码,但原本字母"e"上面修饰符,变成了"l"的修饰符。
产生乱码的原因
以上三例子的错误是在哪个步骤产生的?先来看string.split()之后:
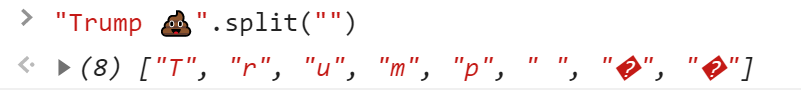


显然在split()方法就已经出错了,并且 长度为n的字符串,转化成了n+1长度的数组。
本质原因要回溯到javascript字符编码的方式。
Unicode与JavaScript详解 - 阮一峰的网络日志
JavaScript语言采用Unicode字符集,最初使用的字符编码是UCS-2!
但UCS-2 编码方式只覆盖基本多语言平面(BMP)的码点,因为 16 位二进制表示的最大值为 0xFFFF,而对于增补平面中的码点(范围为 0x10000
0x10FFFF,十进制为 655361114111),两字节的 16 位二进制是无法表示的。为了解决这个问题,The Unicode Consortium 提出了通过代理对(surrogate pair)机制来扩展原来的 UCS-2 编码方式,也就是 UTF-16。
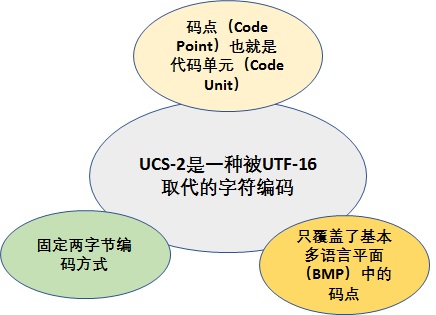
可以这么理解,JavaScript字符编码是 UCS-2 + 代理对(surrogate pair)。
代理对规定用两个16位编码单元来表示一个码位(超出BMP的码位),基实现方式相对有些复杂,本文不赘述。
因为代理对,JavaScript字符串里的字符有两种:
- 由一个码元(16位)表示的BMP字符
- 由两个码元(16*2位)表示的辅助平面字符
这就给 JS 中的 Unicode 处理带来了很多问题,基本上所有的字符串操作函数在处理非 BMP 字符时都是错误的。
“💩”与“𠮷”这两个字符都是通过代理对表示的,有2个码元长度,所以js把它们当成2个字符,长度变成n+1。同时这两个单独的码元所指向的码点上没有相应字符,变成了乱码。
解决方法
1 ES6 自动识别
ES6 中的for of 、array.from(str)、… 都可以自动识别两个码元字符,把它当成一个字符。
[... "Trump 💩"].reverse().join("");
"💩 pmurT"

Array.from("𠮷野家").reverse().join("");
"家野𠮷"

2 引入ssrever 类库
mathiasbynens/esrever: A Unicode-aware string reverser written in JavaScript.
var input = 'Lorem ipsum 𝌆 dolor sit ameͨ͆t.';
var reversed = esrever.reverse(input);
console.log(reversed);
// → '.teͨ͆ma tis rolod 𝌆 muspi meroL'
esrever.reverse(reversed) == input;
// → true
复合字符
但是"noël"的逆转还是不成功。
Array.from("noël").reverse().join("");
"l̈eon"

这个问题和 JS 没关系,是 Unicode 字符集本身的问题。
根据 Unicode 定义,有些字符属于修饰字符,也就是和别的字符一起出现的时候会修饰别的字符,两个合在一起构成一个我们人眼中的字符。
比如,ë 这个字符,由两个 Unicode 码点构成,分别是 U+0065 和 U+0308。这两个都是 Unicode 中的合法字符,拥有自己的码点,但他们合在一起的时候,构成一个我们人类眼中的字符。
同时,在 Unicode 中,还有一个单独的字符 ë,码点为 U+00EB。
ë 和 ë 在我们眼中是一样的字符,但在 Unicode 中却是不同的表现,一个是由两个字符拼接而成,另一个是独立的字符,因此,如果直接比较的话,肯定是不相等的。
"ë" === "ë" // false
这时候就需要引入规整化,将字符转变为某种特定的形式。Unicode 中定义了四种形式,常用的两种是:
- NFD: Normalization Form Canonical Decomposition,将所有的单个的复合字符转换为多个字符拼接而成的形式
- NFC: Normalization Form Canonical Composition,将所有的拼接而成的符合字符转换为单个字符的形式
因此,在比较 Unicode 字符串之前,我们需要对两边的字符串规整化到相同的形式,这样结果才是准确的。ES6 中引入的 String.prototype.normalize 方法可以用于字符串的规整化。
"ë".normalize("NFC") === "ë".normalize("NFC") // true
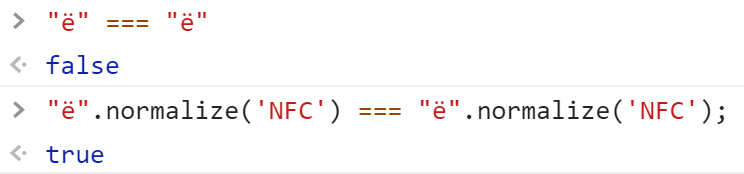
所以,正确反转“noël”需要先将其规整化。
Array.from("noël".normalize()).reverse().join("");
"lëon"

参考资料
