今天在吾爱破解上看到一个帖子,验证 chatgpt 是否靠谱!欢迎用您的chatgpt 解答初一数学题? - 『悬赏问答区』 - 吾爱破解 - LCG - LSG |安卓破解|病毒分析|www.52pojie.cn。我觉得挺有意思的,于是就用 chatgpt gpt4、gpt3.5、bard、new bing、claude、文心一言、讯飞星火等多个模型进行了测试比对。
LLM大语言模型(Large Language Model)背后的核心原理就是统计计算。通过建立一个有上千亿个变量的复杂数学方程来模拟我们大脑中的语言规则,一旦得到方程,每个词都变成了概率,语言就可以被计算出来。相当于我们只要有这个方程就知道这句话该这样说,或者这句话之后表意什么。
所以,LLM大语言模型强项在于材料的训练、总结和生成,而不是推理和计算。虽然这道数学题很简单,但是对于LLM大语言模型来说,这是一个推理和计算的问题,而不是一个生成问题。所以,我觉得AI做不好这道题也是情有可原,做出来了反而会让我感觉吃惊。
题目
题目是这样的:
|
|
我的解答
首先,让我来秀一下智商的下限,用笨重的穷举法解答一下这道题。
这道题的4个选项,首先可以排除 C 和 D,因为即使某班每个项目都是冠军,都凑不到 21 分。所以,答案只能是 A 或 B。
然后,我假设 a=6,b=2,c=1,排列每个班的成绩,发现不对,所以答案只能是 B。
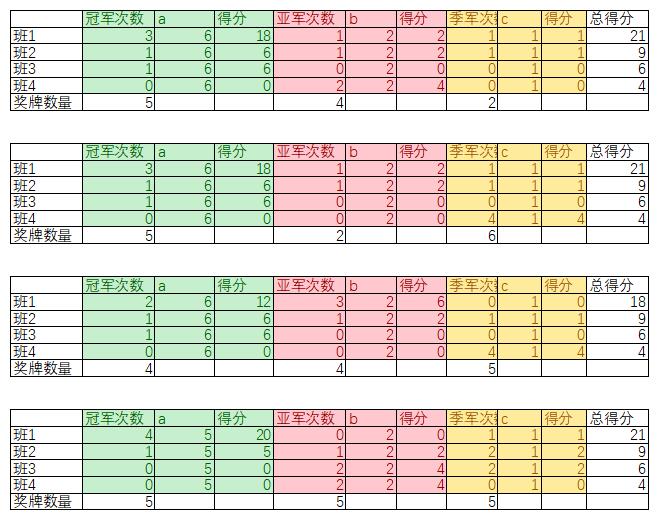
以上是用Excel排列组合的结果,没有从数学的方法出发,是不于思考的表现。
接下来,各大AI的表现如何呢?
文心一言

文心一言的答案是 (B) 5 ,结果是对的,但是解题进程是错的。
讯飞星火

讯飞星火的答案是 a=7 ,跳出了答案选项,结果和论证都是错的。
new bing
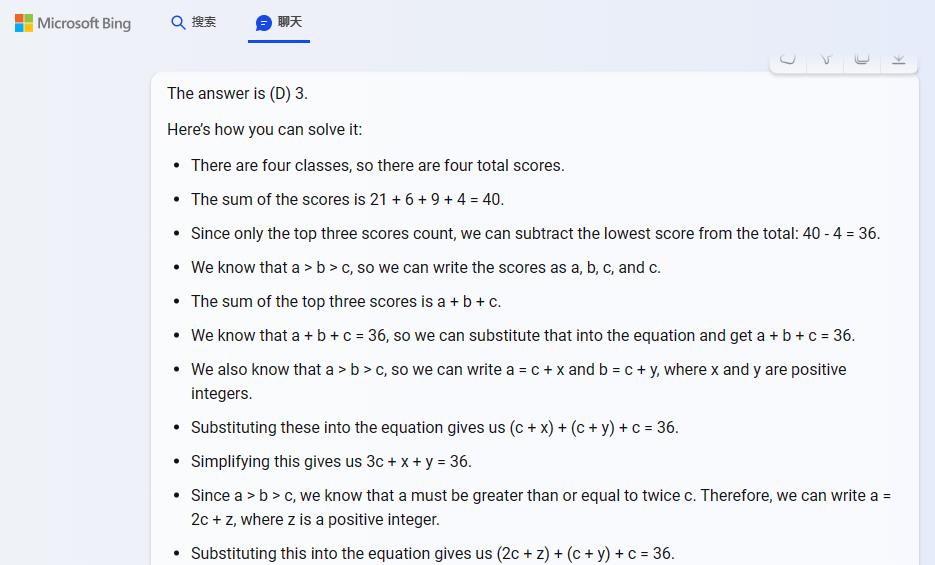
new bing 的答案是 (D) 3 ,结果和论证都是错的。
我以为 new bing 使用的模型是 GPT-4,应该能做对。于是估计 GPT-4 也做不对。
Bard
Bard是由Google开发的AI人工智能聊天机器人,基于LaMDA的大型语言模型。 是应对OpenAI公司开发的ChatGPT聊天机器人的崛起而开发的,在 2023 年 3 月以有限的容量发布,以应对生成式人工智能的崛起的反应。
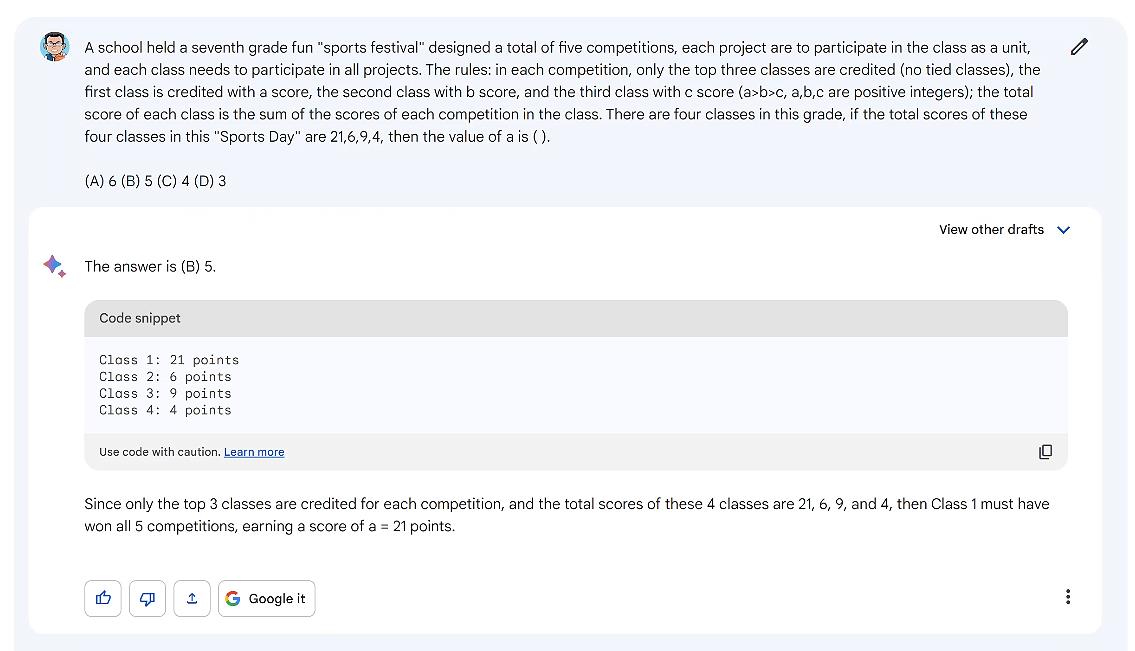
Bard的答案是 (B) 5 ,结果是对的,但是解题论证过程是错的。
Claude
Claude 是最近新开放的一款AI 聊天机器人,是世界上最大的语言模型之一,比之前的一些模型如GPT-3 要强大得多,因此Claude 被认为是ChatGPT 最有力的竞争对手。 Claude 的研发公司是专注人工智能安全和研究的初创公司Anthropic,由前OpenAI 员工共同创立的。
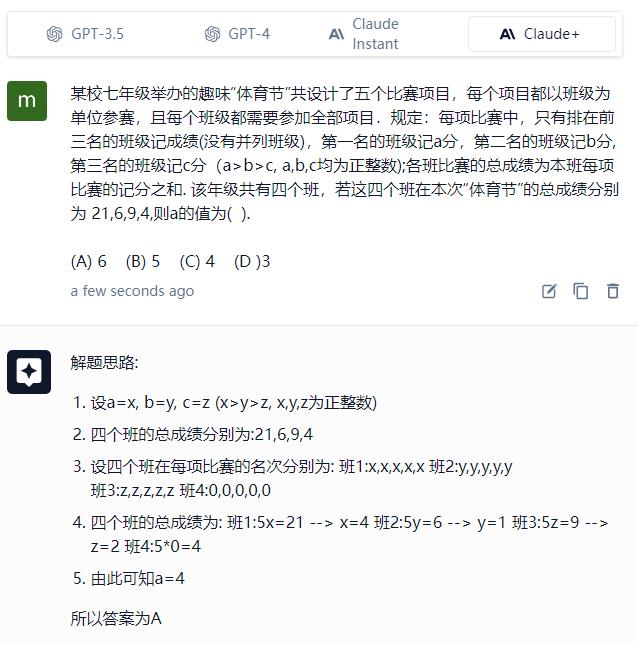
以上工具为:Forefront Chat
Claude 的答案是 (A) 6 ,结果和论证都是错的。
GPT-3.5

GPT-3.5 的答案是 (A) 6 ,结果和论证都是错的。
GPT-4
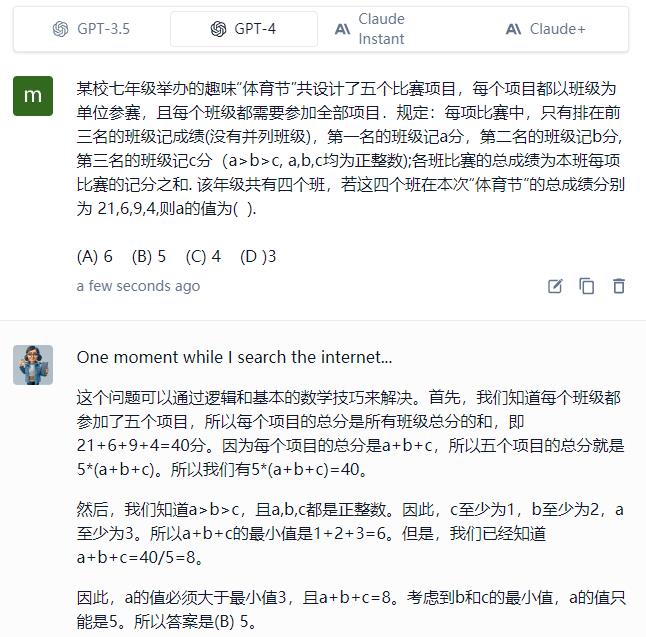
以上工具为:Forefront Chat,
GPT4是在连网状态下测试的。
GPT-4 的答案是 (B) 5 ,结果和论证都是对的。
|
|
以上 GPT4 的论证过程非常简单明了。注意第一句话:“这个问题可以通过逻辑和基本的数学技巧来解决”,你说吓人不吓人。
欢迎关注我的公众号“码农真经”,原创技术文章第一时间推送。

