最近给字幕工具箱写了个简繁转换的小工具,需要检测输入文本是简体还是繁体。这里记录一下检测和转换的方法。
https://zm.i8k.tv/stc
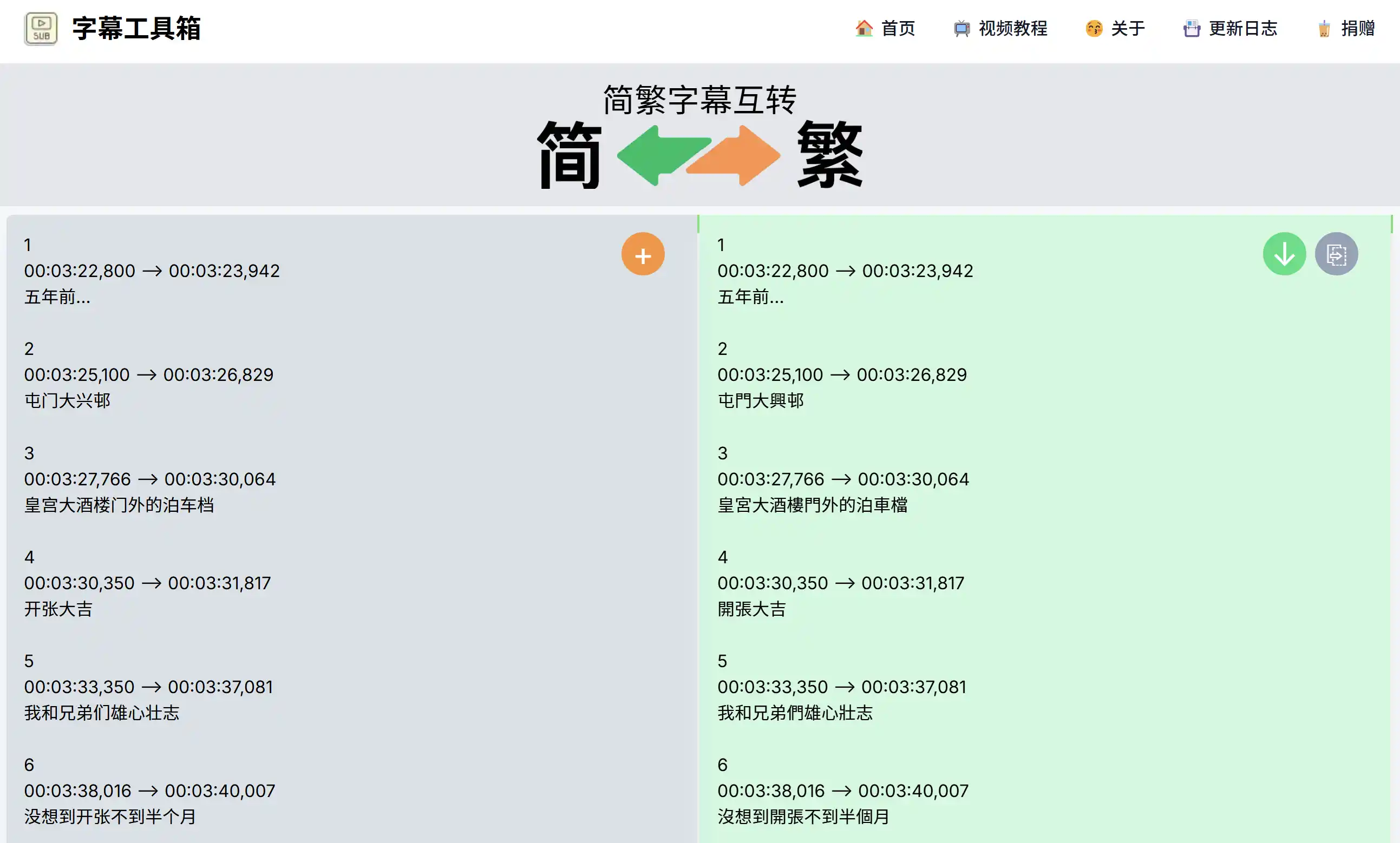
简繁转换
GitHub - nk2028/opencc-js: The JavaScript version of Open Chinese Convert (OpenCC)
简繁转换的库有很多,这里使用了 OpenCC (Open Chinese Convert 开放中文转换) 的 JavaScript 版本。使用方法如下:
1
2
3
4
5
6
7
8
|
import * as OpenCC from 'opencc-js/core';
import * as Locale from 'opencc-js/preset';
const isTrad = isTraditional(text.slice(0, 1000));
const converter = isTrad ?
OpenCC.ConverterFactory(Locale.from.hk,Locale.to.cn)
: OpenCC.ConverterFactory(Locale.from.cn,Locale.to.hk);
const converted = converter(text);
|
代码还是挺简单的,毕竟用的是现成的库。但奇怪这个库没有提供简繁检测的方法,只能自己写了。
检测简繁
Copilot 的方法
起先我让 GitHub Copilot 帮我写,它给出了这个方法:
1
2
3
4
5
6
7
8
9
10
11
|
function isTraditionalChinese(text) {
// 繁体字的 Unicode 范围
const traditionalChineseRange = /[\u3400-\u4DBF\u4E00-\u9FFF\uF900-\uFAFF]/;
// 检查字符串中是否包含繁体字
return traditionalChineseRange.test(text);
}
// 示例用法
console.log(isTraditionalChinese("體")); // true
console.log(isTraditionalChinese("体")); // true
|
这个方法的意思是,去检查字符串中是否包含繁体字的 Unicode 范围。但试验结果是不对的。估计是因为繁体字的 Unicode 范围不准确。但不失为一个好的思路。
cjk - What’s the complete range for Chinese characters in Unicode? - Stack Overflow
现成类库
nickdrewe/traditional-or-simplified: Detect if a string contains traditional or simplified Chinese characters
找了个类库,看了一下它们的实现。
traditional-or-simplified/TradOrSimp.js at master · nickdrewe/traditional-or-simplified
这个类库引入了所有简体字和繁体字,然后检查输入文本中是否包含这些字。这个方法的缺点是,需要引入大量的字典,不适合我的场景。并且它还要记录简体字、繁体字的数量,如果简体字数量多,就认为是简体字,反之亦然。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
function detect(str){
var result = {
inputLength: str.length,
simplifiedCharacters: 0,
traditionalCharacters: 0
}
for(var i = 0; i < str.length; i++){
var char = str.substr(i, 1)
if(charIsS(char)){
result.simplifiedCharacters++
}else if(charIsT(char)){
result.traditionalCharacters++
}
if(i == str.length -1){
if(result.simplifiedCharacters > result.traditionalCharacters){
result.detectedCharacters = 'simplified'
result.detectionRate = result.simplifiedCharacters / result.traditionalCharacters | 1;
}else if(result.simplifiedCharacters < result.traditionalCharacters){
result.detectedCharacters = 'traditional'
result.detectionRate = result.traditionalCharacters / result.simplifiedCharacters | 1;
}else{
result.detectedCharacters = 'unknown'
result.detectionRate = 0;
}
return result
}
}
}
|
简单方法
以上的实现我觉得是比较奇怪的。一般而言,文本中如果出现过一两个繁体字,就可以认为是繁体文本。所以我写了一个简单的方法:
1
2
3
4
|
const isTraditional = (text: string) => {
const commonTraditionalChars = "這為來個們說國時於會後對著裏過發軍無麽經當與學進種將還見沒從給動臺麼車開現長裡業電兒實頭氣樣間體媽親灣愛機請問邊選剛結牽確淚靈塊錢謝變";
return [...text].some((char) => commonTraditionalChars.includes(char));
}
|
这个方法的思路是,检查文本中是否包含常见的繁体字。如果包含,就认为是繁体文本。这个方法的优点是简单,缺点是不够准确。但对于我的场景,已经足够了。
那么常见的繁体字是哪些呢?我们可以先找出常见的汉字,然后找出其中的简繁不同的字,这样就可以得到常见的繁体字了。
100个最常见的汉字
在检查繁体字时候,我发现好多字居然都有繁体,举个例子:没钱吃饭中的“没”字的繁体是“沒”,长得还是挺像的。而“着火”中的“着”字的繁体是“著”,而这个“著”字在简体中也有,所以我很好奇繁体如何区分这两个字。
当然,繁体字本身也有很多变体,这里只是简单的检测方法。
参考资料
