
概要
Whisper是OpenAI推出的一种开源语音识别(ASR)模型,能够自动识别多种语言,将音频转换文字。Whisper由python实现,同时拥有丰富的社区支持。除了原始的Whisper之外,还有一些相关的项目,有移植到 C/C++的whisper.cpp和能使用GPU加速的 faster-whisper 。如果你不懂编程或者不熟悉命令行,也有也有很多开发者开发了图形界面,比如buzz和Const-me/Whisper等。
常用术语
收集资料时,发现有些术语或缩写需要解释一下:
- ASR(Automatic Speech Recognition):自动语音识别,将语音信号转换为文本。
- VAD(Voice Activity Detection):语音活动检测,用于识别音频中的语音片段。
- WER(Word Error Rate):字错误率,用于评估语音识别系统的准确性,计算为识别错误的单词数与总单词数之比。
原生Whisper(OpenAI Whisper)
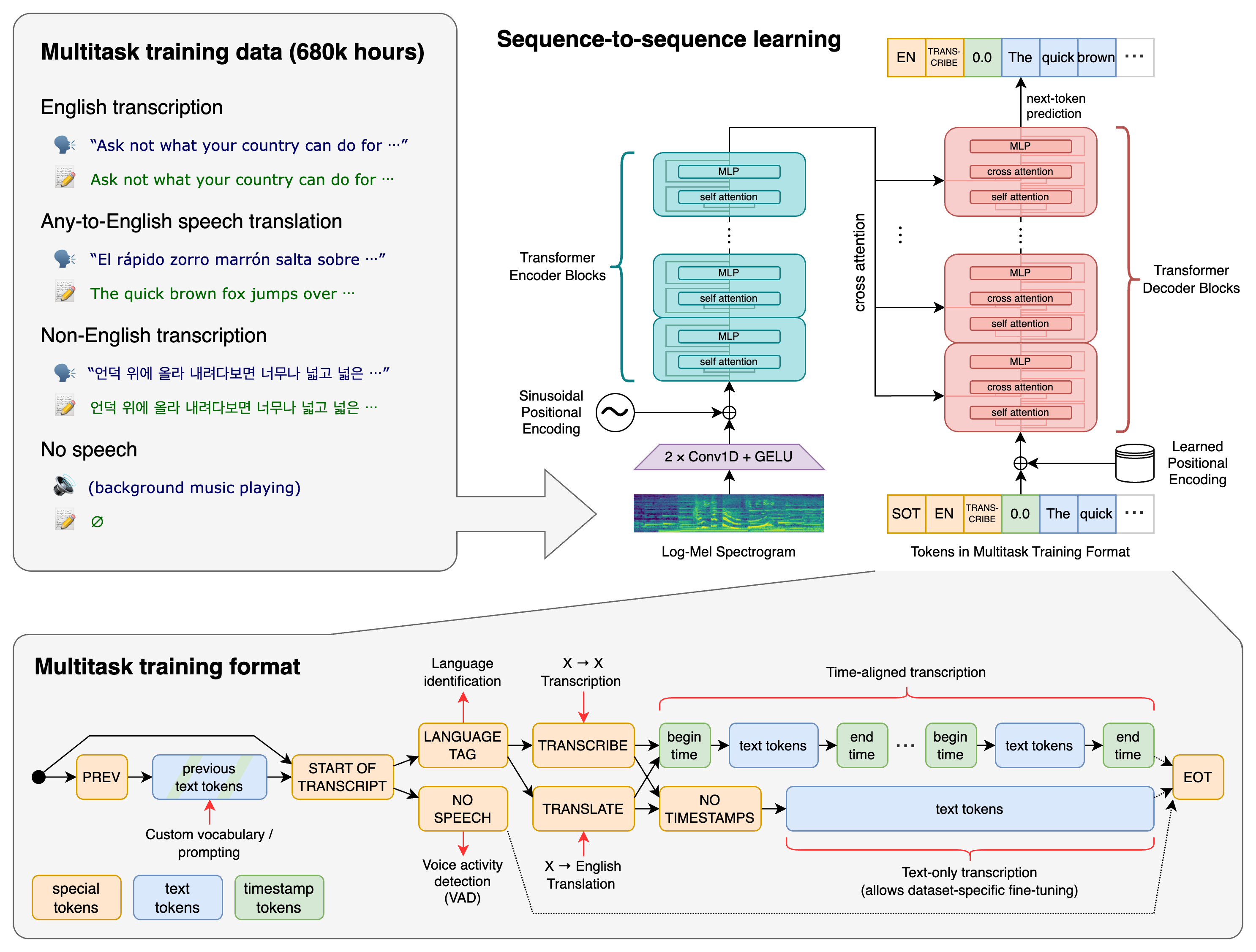
OpenAI官方发布的基础版本,基于编码器-解码器Transformer架构,支持99种语言的语音识别、翻译、语言检测和语音活动检测。输入音频被分割为30秒片段并转换为对数梅尔频谱图,通过多任务学习实现高效处理。
提供多种模型(如Tiny、Base、Small、Medium、Large),参数从39M到1550M不等,用户可根据需求在速度和精度间权衡。
适用于通用语音转录、多语言翻译及零样本学习任务。
Whisper的训练方法
Whisper.cpp
Whisper.cpp是Whisper模型的C/C++移植版本,具有无依赖项、内存使用量低等特点,重要的是增加了Core ML支持,完美适配苹果M系列芯片。
在macOS上,Whisper.cpp比faster-whisper更快,尤其在苹果M芯片上表现优异。它的张量运算符针对苹果M芯片的CPU进行了大量优化,使用Arm Neon SIMD instrisics或CBLAS Accelerate框架例程。
适合需要在macOS上高效运行的用户,尤其是使用苹果M系列芯片的用户。
这里说一下 whisper.cpp 背后的作者:Georgi Gerganov。
Georgi Gerganov 宣布创立一家新公司 ggml.ai,旨在支持 ggml 的开发。ggml 是 Georgi Gerganov 使用 C/C++ 构建了机器学习张量库,能够帮助开发者在消费级硬件上实现大模型,并提升模型性能。
作为纯 C 语言编写的框架,ggml 大幅降低了大模型的运行成本。llama.cpp 和 whisper.cpp 都使用了 ggml 库。
Faster-Whisper
faster-whisper 是使用 CTranslate2 重新实现 OpenAI 的 Whisper 模型,CTranslate2 是 Transformer 模型的快速推理引擎。
CTranslate2 是一个 C++ 和 Python 库,用于使用 Transformer 模型进行高效推理。
Faster Whisper 实现速度比 openai/whisper 快 4 倍,精度相同,同时占用的内存更少。在 CPU 和 GPU 上通过 8 位量化可以进一步提高效率。
部署不易,于是有人做了faster-whisper的单文件可执行版本:

WhisperX
- 增强功能:整合了语音活动检测(VAD)、分段批处理和强制对齐技术。通过VAD分割音频片段,结合外部音素模型对齐单词级时间戳,显著提升时间戳准确性。
- 性能:在长音频处理中,推理速度更快且错误率(WER)更低,适用于需要高精度时间戳的应用(如字幕生成)。
- 依赖库:结合Pyannote-audio和Phoneme模型实现多阶段处理。
WhisperX的工作流程
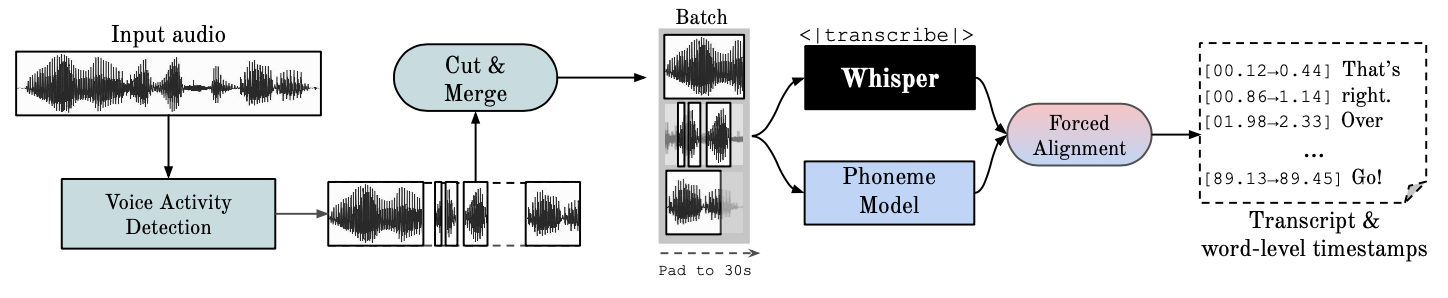
- VAD:使用Pyannote-audio进行语音活动检测,分割音频片段。
- 音频处理:将分割后的音频片段输入Whisper模型进行转录,生成初步的文本输出。
- 音素对齐:使用Phoneme模型对转录文本进行音素级对齐,生成单词级时间戳。
基于音素的 ASR 一组经过微调的模型,用于识别区分一个单词和另一个单词的最小语音单位,例如“tap”中的元素 p。一个流行的示例模型是 wav2vec2.0。
- 后处理:结合VAD和音素对齐结果,生成最终的转录文本和时间戳输出。
- 输出格式:支持多种输出格式,如SRT、VTT等,方便后续字幕处理。
Distil-Whisper
- 压缩方法:由HuggingFace通过知识蒸馏技术压缩Whisper Large模型,参数量减少50%,速度提升6倍,同时保持相近的准确率(WER仅增加1%)。
- 训练数据:使用21,170小时公开语音数据,通过伪标签和KL散度损失优化。
- 适用场景:适合需要低延迟且对资源敏感的实时转录服务。
Whisper-Medusa
aiOla是一家总部位于以色列的公司,成立于 2019 年,专注于为纸质工作流程数字化提供人工智能驱动的解决方案。
aiOla推出了开源人工智能模型Whisper-Medusa,旨在提高自动语音识别能力。结合 OpenAI 的 Whisper 和 aiOla 的技术,Whisper-Medusa 声称其运行速度比 Whisper 本身快 50%。该模型支持 100 多种语言,可将非结构化语音数据转化为可操作的见解,在航空、物流和医疗保健等行业大有可为。
aiola-lab/whisper-medusa: 与美杜莎头的耳语 — aiola-lab/whisper-medusa: Whisper with Medusa heads
- 加速技术:引入Medusa头并行预测多个后续token,减少自回归解码的步数,推理速度提升1.5倍,部分语言WER甚至优于原版。
- 代价:因增加额外解码头,显存占用略有上升。
- 适用性:适合对实时性要求高的交互式应用(如实时语音助手)。
Whisper-JAX
JAX,是用于变换数值函数的Python机器学习框架,它由Google开发并具有来自Nvidia的一些贡献。它结合了修改版本的Autograd,和OpenXLA的XLA。它被设计为尽可能的遵从NumPy的结构和工作流程,并协同工作于各种现存的框架如TensorFlow和PyTorch。
WhisperJax 基于 JAX 框架,支持 TPU/GPU 并行计算,理论速度更快(需具体测试)10。
社区支持较少,部署门槛较高。
适用需要大规模分布式计算的研究或生产环境。
其他相关实现
- Whisper API集成:通过OpenAI的API直接调用,支持实时转录和翻译(仅限转译为英文),但需考虑数据隐私和成本。
- 本地部署:用户可下载模型本地运行,结合Hugging Face或自定义环境实现离线应用。
- 多模态扩展:例如与ChatGPT结合,构建能听会说的机器人,或与图像生成模型(如Stable Diffusion)联动,实现语音驱动创作。
选择建议
| 需求优先级 | 推荐模型 | 理由 |
|---|---|---|
| 实时性与低资源占用 | faster-whisper | 速度最快,内存优化,支持量化,内置 VAD 减少冗余输出。 |
| 精确时间戳与多人分离 | whisperX | 强制对齐技术提升时间戳精度,支持说话人分离。 |
| 英文场景与极速响应 | Distil-Whisper | 体积小、速度快,适合嵌入式设备和英文实时任务。 |
| Mac 或低依赖性本地部署 | whisper.cpp | C++ 实现轻量化,Core ML 加速优化,适合跨平台和移动端。 |
| 多语言与高准确性 | OpenAI Whisper | 官方模型功能全面,支持翻译和多任务处理。 |
| 高性能 GPU 批量处理 | Whisper-Medusa | 并行推理加速,适合大规模数据处理。 |
应用与案例
我写的工具网站:免费字幕软件一站式下载 - 字幕工具箱 - 字幕工具箱,整理了很多字幕软件,其中很多工具是基于 Whisper 的。

下一篇文章将介绍一些基于 Whisper 的应用和案例,包括如何在实际项目中使用 Whisper 进行语音识别和转录。
