2025年11月18日11:20 UTC ,Cloudflare的网络开始经历重大故障,无法传输核心网络流量。北京时间(中国标准时间,CST)比世界协调时(UTC)快8个小时,所以,我是晚上回到家才发现。虽然我不逛x.com、OpenAI、Spotify等,但发现好几个摸鱼的网站都无法访问。此次故障持续了将近6个小时,真切的感受到互联网的“瘫痪”。
事件概述
- 发生时间: 2025年11月18日 11:20 UTC
- 持续时间: 核心服务约3小时10分钟基本恢复,全部服务完全恢复耗时约5小时46分钟(至17:06 UTC)。
- 影响范围: Cloudflare全球网络的核心流量处理能力,导致大量用户访问托管在Cloudflare上的网站时出现错误页面。
- 根本原因: 并非网络攻击,而是一次数据库权限变更引发连锁反应,最终导致核心代理软件崩溃。
关键时间线
| 时间 (UTC) | 事件 |
|---|---|
| 11:05 | 部署数据库权限变更。 |
| 11:28 | 影响开始,首次在客户流量中观察到错误。 |
| 11:32-13:05 | 团队调查,初期怀疑是DDoS攻击或Workers KV问题。 |
| 13:05 | 对Workers KV和Access实施绕过,影响部分减小。 |
| 13:37 | 确认Bot Management特征文件是根本原因。 |
| 14:24 | 停止创建和传播错误的特征文件。 |
| 14:30 | 核心影响解决,大部分服务恢复正常。 |
| 17:06 | 完全恢复,所有服务正常,事件结束。 |
| 2025年11月19日 | Cloudflare的股价在早盘交易中一度下跌了7%。 |
| 2025年11月19日 | 官方发布详细故障报告。 |
故障分析与技术细节
一、 故障根源:一次变更引发的连锁反应
本次故障并非由网络攻击导致,其根本原因是一次旨在提升数据库安全性的权限变更所触发的连锁反应:
- 触发点:当日11:05 UTC,Cloudflare对ClickHouse数据库进行了权限变更,使用户能查询到更多底层表。
- 数据异常:此举导致Bot Management系统生成机器学习特征文件的数据库查询,返回了包含大量重复条目的结果,致使最终生成的特征文件体积翻倍。
- 系统崩溃:翻倍后的特征文件超出了核心代理软件为保障性能而设置的内存预分配限制。软件在读取该文件时触发未处理错误而崩溃,无法处理用户请求,进而返回大量HTTP 5xx错误。
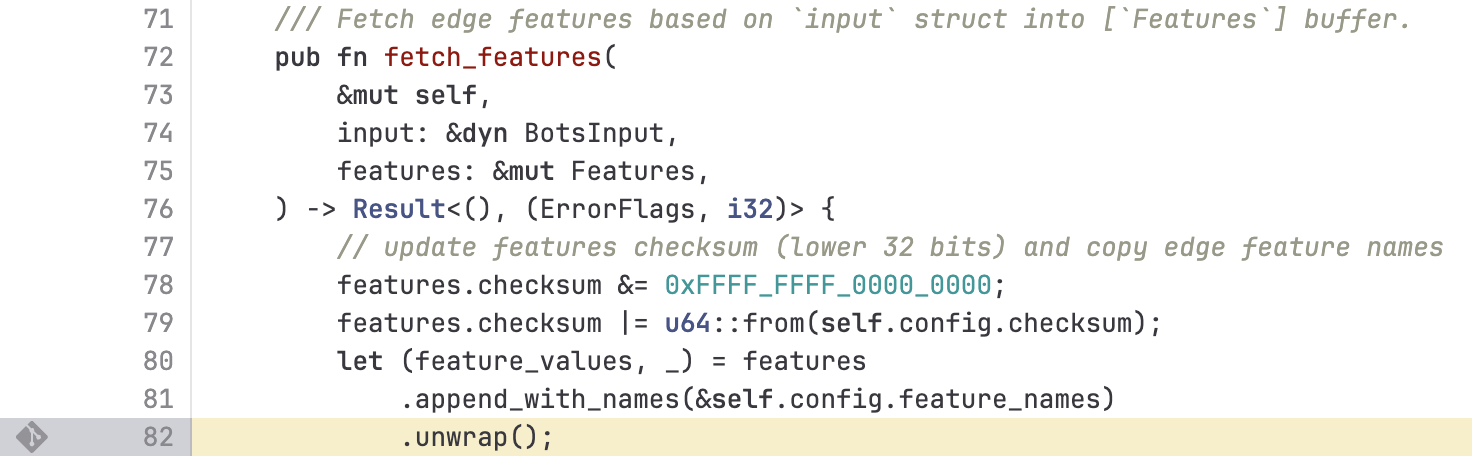
以上代码导致线程崩溃,进而引发了 5xx 错误:
bash thread fl2_worker_thread panicked: called Result::unwrap() on an Err value
.unwrap() 会在遇到 Err 值时直接panic。线程panic是指线程在执行过程中遇到无法恢复的严重错误,导致程序立即终止执行的一种状态。
所以,故障源于Cloudflare系统内部的自动化或人工智能配置出错,生成了一个过于庞大、系统无法处理的文件,导致其服务“闸门”关闭,互联网因此部分瘫痪。简言而之,都是人工智能惹的祸😂。
二、 复杂诊断与恢复过程
故障现象因特征文件每五分钟更新一次而呈现波动性,时好时坏,这给诊断带来了极大困难,导致团队初期误判为超大规模DDoS攻击。在排除攻击可能性后,团队最终锁定根本原因。
恢复措施主要包括:
- 停止传播:停止生成和分发错误的特征文件。
- 文件回滚:用已知良好的早期版本替换异常文件。
- 服务重启:强制重启全球网络中的核心代理服务。
最终,核心服务在14:30 UTC基本恢复,全部服务在17:06 UTC完全恢复正常。
三、 广泛的服务影响
此次故障波及范围广泛,包括:
- 核心服务:CDN、安全服务大量返回5xx错误。
- 关联服务:Turnstile、Workers KV、Cloudflare Access身份验证失败。
- 管理平台:因登录依赖Turnstile,大多数用户无法访问仪表板。
四、 教训与改进承诺
Cloudflare对此深表歉意,并已启动改进计划,核心方向包括:
- 像处理不可信输入一样,严格验证内部生成的配置文件。
- 为关键功能增加全局熔断机制,以便快速止损。
- 优化错误处理流程,防止可观测性系统在故障时加剧资源消耗。
Cloudflare是什么?
Cloudflare是一家全球云平台,其核心角色是作为用户和网站源服务器之间的中间层。它通过其强大的边缘网络,在全球330多个数据中心提供内容和服务,使网站能更快地加载,并防御恶意流量攻击。
Cloudflare被比喻为互联网的“防洪系统”,其主要作用是:
- 安全防护:保护网站免受DDoS攻击、恶意机器人程序等网络安全威胁。它就像一个防火墙,过滤异常流量并隐藏网站源服务器的真实IP地址。
- 性能加速:通过其内容分发网络(CDN),将网站内容的副本缓存在世界各地的服务器上。当用户访问网站时,内容会从离他最近的服务器提供,从而显著提升加载速度。
- DNS解析:提供快速、可靠的域名解析服务(DNS),将域名转换为IP地址,这是用户访问网站的关键第一步。Cloudflare还面向普通用户提供免费的公共DNS服务“1.1.1.1”,以保护用户隐私。
赛博活佛
IT人士将Cloudflare称为“赛博菩萨”或“赛博活佛”,主要源于Cloudflare长期提供的慷慨免费服务计划,这让众多开发者和中小网站能够以极低的成本,享受到企业级的网络加速和安全防护。
Cloudflare提供了大量的普惠服务,如CDN(内容分发网络)、DNS解析、DDoS攻击防护、SSL证书等在内的多种免费服务。正如一些报道所言,一个“破论坛”都能在上面免费获得保障,这种模式极大地降低了建站和运营的门槛。
Cloudflare浑身都是宝,普通用户能白嫖多少服务?盘点cloudflare的免费功能 #cloudflare #网站 #网络 #服务器 #域名 - YouTube
市场份额有多大?
Cloudflare在它所处的“互联网管道”领域占据着主导地位,全球有超过20%的网站使用Cloudflare的网络,其中包括大量知名平台和17%的《财富》1000强企业。
| 领域 | 市场份额估计 | 说明 |
|---|---|---|
| 反向代理服务 | 约 82% | 这标志着它在关键互联网基础设施中的核心地位。 |
| CDN提供商 | 约 34% | 是全球最大的CDN服务商之一。 |
| 网络流量处理 | 约 20% | 每天处理巨量的网络请求。 |
对全球互联网的影响
Cloudflare巨大的市场份额使其成为互联网生态系统的关键节点,这也带来双面影响。
-
积极影响:
- 提升体验:它让各种规模的网站都能以较低成本获得企业级的安全和性能,使互联网整体更快速、更安全。
- 保障稳定:帮助网站应对突发的高流量和恶意攻击,维持在线服务的稳定。
-
风险暴露:服务集中的脆弱性
2025年11月18日,Cloudflare发生了一次全球性服务故障,这次事件像一次“压力测试”,充分展示了其影响力。- 多米诺骨牌效应:由于众多大型网站都依赖Cloudflare,其单一技术故障导致X (Twitter)、ChatGPT、Canva、PayPal等看似不相关的平台在短时间内相继中断服务。
- 关键基础设施中断:一些金融机构的数字银行服务也受到波及,出现了间歇性连接问题。
- 互联网的“单点故障”:这次事件警示,现代互联网基础设施存在集中性风险。当少数几家关键服务提供商出现问题时,其影响会迅速蔓延至全球网络。
总结
虽然Cloudflare 是赛博菩萨,但我没有使用过,正好借这篇文章简单了解一下。不看不知道,一看吓一跳,原来 Cloudflare 这么重要!
所以,个人觉得Cloudflare这次宕机事件,相较于 2024年7月发生的 CrowdStrike 蓝屏事件更为严重。因为,CrowdStrike影响的是终端电脑,而Cloudflare影响的是网络服务器,背后是无数的终端。
此次事件深刻揭示了,在高度复杂的分布式系统中,一个微小的内部变更若未经过充分评估,也可能通过连锁反应导致全局性瘫痪,凸显了变更管理与系统韧性设计的极端重要性。
像Cloudflare、亚马逊云服务(AWS)、微软Azure这类占据垄断地位的互联网基础设施公司,一旦出事影响巨大。所以,还是要加强监管和问责机制。
当前互联网上的恶意流量(来自罪犯和国家行为体)规模空前,互联网基础设施的“坑洼”已经开始显现,整体环境正变得日益危险和不稳定。所以,大家还是要珍惜安静上网的美好时光,即便在网络世界,也要少一点戾气。
最后提醒大家,不要“将所有鸡蛋放在一个篮子里”。
