
Python 自动化神器 Clicknium 爬虫实战_哔哩哔哩_bilibili
Clicknium是一个Python界面自动化库,可以非常简单直观地使用它操作浏览器和Windows平台APP。
Python有很多自动化的库,比如Selenium,Pyautogu,Playwright。有的只能操作网页,有的只能操作App,并且使用起来都算不上简单:Selenium需要安装Driver,需要学习XPath;Pyautogui使用简单,代码可读性强,完全模拟鼠标单击,双击拖动;但是它采用xy轴的方式定位桌面元素。分辨率变化,位置变化都会影响运行。要想用好这些工具,学习成本实在不低。
Clicknium的出现,让Python界面自动化变得简单直观。Clicknium提供了简洁直观的API来操作UI元素,如set_text, get_text, click 等等。查看代码时,逻辑非常清晰,贴近自然语言和实际操作。那怎么解决元素定位的问题。我们为此设计了Clicknium Recorder。打开Recorder,Clicknium会自动识别鼠标所指的元素。 按住Ctrl+鼠标单击,Recorder会自动抓取元素,生成Locator。直接使用 Locator就能直接获取UI元素并对其进行操作。
安装
Clicknium支持Python 3.7+,安装过程非常简单,主要有三个步骤:
- 安装Clicknium库
pip install clicknium
- 安装 VSCode 插件 Clicknium extension
- 安装浏览器插件(在第2步安装vscode插件时,会提示安装第1步及第3步)
第一个自动化项目
First Automation Project | Clicknium
实际案例
我最近发现一个必应壁纸的非官方网站 今日必应,每天都会更新一张图片,我们可以使用Clicknium来爬取这些图片。爬取思路就是找到起始页的所有图片链接,然后打开每个链接,下载图片。
1 初始化项目
VSCode 安装Clicknium 插件之后,同时也会安装Clicknium CLI。我们可以使用CLI来初始化项目。
ctrl + shift + p 打开 VSCode 命令窗口Clicknium:Create Project 创建项目
2 捕获Locator元素
打开今日必应的网站,我们可以看到有很多图片,我们想要抓取这些图片,首先我们需要抓取图片的链接。我们可以使用Clicknium Recorder来抓取元素。
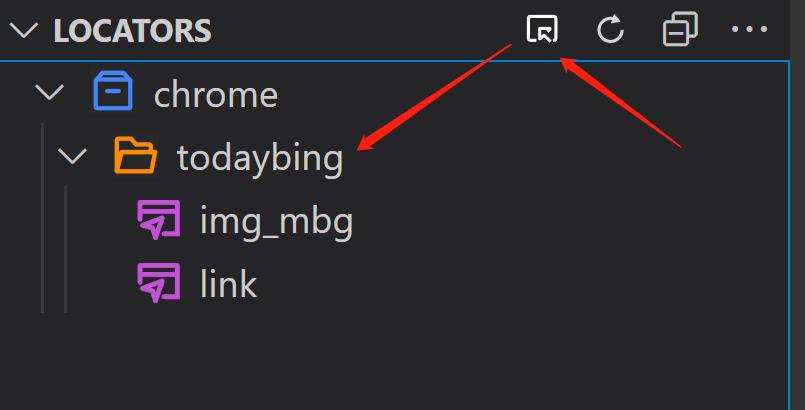
在VSCode中Locators面板中,点击右上角捕获按钮,选择打开的Chrome浏览器,打开相应网站,按ctrl点击元素,即可抓取元素。

3 编写代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
# app.py
from clicknium import clicknium as cc, locator, ui
import requests
def main():
tab = cc.edge.open("https://www.todaybing.com")
links = tab.find_elements(locator.chrome.todaybing.link)
for link in links:
new_tab = tab.browser.new_tab(link.get_property("href"))
img = new_tab.find_element(locator.chrome.todaybing.img_mbg)
img_src = img.get_property("src")
download_img(img_src)
new_tab.close()
def download_img(url):
img = requests.get(url)
filepath = './' + url.split("/")[-1] + '.jpg'
with open(filepath, 'wb') as f:
f.write(img.content)
if __name__ == '__main__':
main()
|
4 运行
下一步工作
因为网站是滚动分布,以上简单代码只能爬取网站少许显示的图片。接下来可以通过 Clicknium 向下滑动网页,点击加载更多按钮,从而获得更多的图片链接,达到爬取所有图片的效果。
另也给大家推荐一个爬取妹子图的脚本:
40 行代码搞定 v2ph 爬虫 - V2EX
ReaganScott/v2ph: python爬虫集合
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
import os
from time import sleep
from clicknium import clicknium as cc, locator, ui
import requests
import random
from tkinter import messagebox
tab = cc.chrome.open("https://www.v2ph.com/")
#messagebox.askokcancel('Confirm', 'please do Human check')
elems = tab.find_elements(locator.chrome.v2ph.img_list)
for elem in elems:
url = "https://www.v2ph.com{}".format(elem.get_property("href"))
new_tab = tab.browser.new_tab(url)
has_next_page = True
while has_next_page:
for _ in range(20):
new_tab.scroll(0, 2000)
sleep(0.5)
new_tab.wait_appear(locator.chrome.v2ph.img_sublist)
imgs = new_tab.find_elements(locator.chrome.v2ph.img_sublist)
headers = {
'referer': 'https://www.v2ph.com/',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36',
'Content-Type': 'application/json'
}
for img in imgs:
url = img.get_property("src")
file_name = url.split("/")[-1]
img_file = requests.get(url, headers=headers)
temp_file = os.path.join(os.getcwd(), "picture", "{}".format(file_name))
open(temp_file, 'wb').write(img_file.content)
sleep(random.randint(1,5))
next = new_tab.wait_appear(locator.chrome.v2ph.a_next)
if next != None:
next.click()
else:
has_next_page = False
break
new_tab.close()
sleep(random.randint(1,5))
new_tab.close()
|
免责声明
以上代码仅用于案例学习,与学习无关的事,也与我无关。
