
Pyaudio 简介
PyAudio是Python的一个音频处理模块,它可以让我们在Python中使用音频设备,比如录音、播放音频等。PyAudio是基于PortAudio的,所以它可以在多种平台上使用,比如Windows、Linux、Mac等。
安装
|
|
示例
接下来通过两段代码来演示PyAudio的使用。通过 record.py 可以录音 录制一段 10 秒的音频,然后通过 play.py 可以播放刚刚录制的音频。
录音 recorder.py
|
|
播放 play.py
|
|
录音详解
录音参数
|
|
- CHUNK:每次读取的音频块大小,单位是字节,一般取1024的倍数,比如1024、2048、4096等。
- FORMAT:音频的格式,这里使用的是16位整数,即paInt16。
- CHANNELS:声道数,这里使用的是双声道,即2。
- RATE:采样率,这里使用的是44100,即44.1kHz。
- RECORD_SECONDS:录音的时长,这里是10秒。
- WAVE_OUTPUT_FILENAME:输出的音频文件名。
录音设备
上面的 record.py 虽然实现了录音的功能,但是我们不知道声音的输入是什么?是内录还是外录?
PC录音一般有以下几种声音来源:
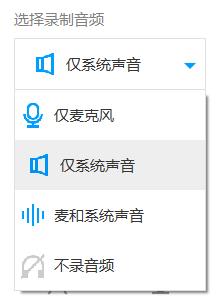
- 外录:麦克风
- 内录:录制电脑上正在播放的声音,即从声卡录制,而不是从麦克风录制
以下是 Windows 系统下录音的几种方式:
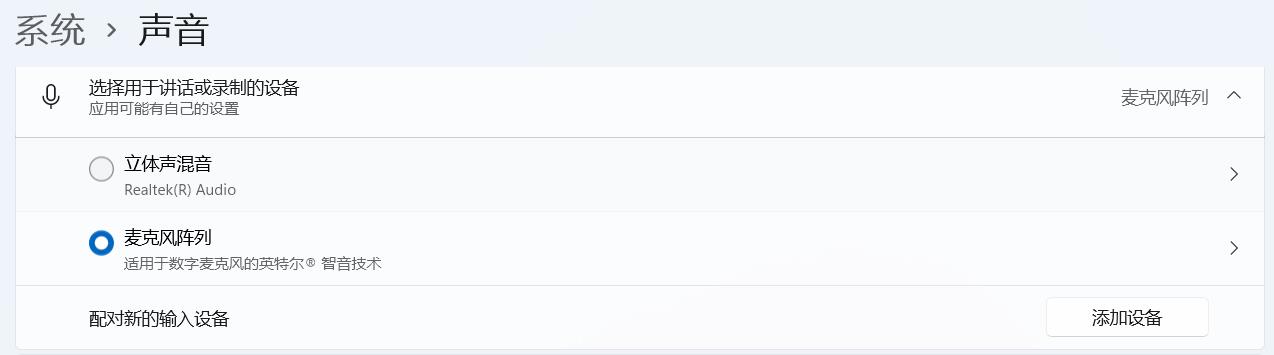
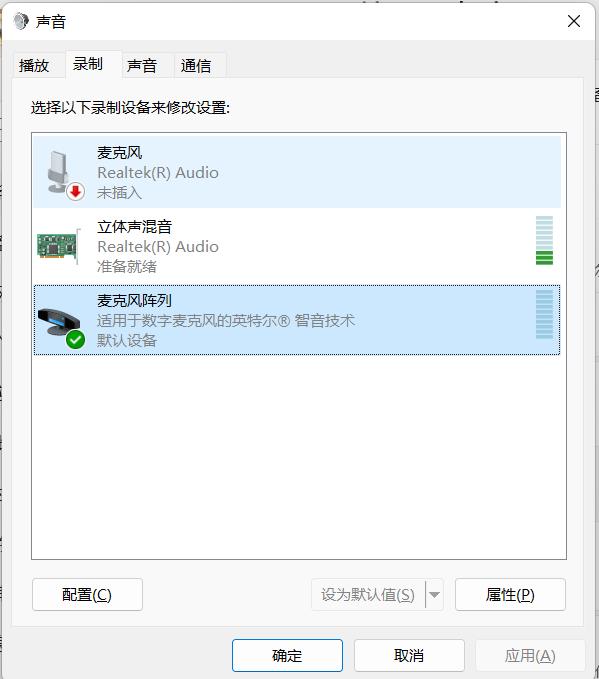
录音设备列表
在 PyAudio 不指定录音设备的情况下,它会自动选择系统默认的录音设备,比如上面的 麦克风陈列,也就是我们常说的外录。而立体声混音即是内录,内录须在声音面板启用立体声混音。
那么如何指定录音设备呢?我们可以通过 PyAudio 的 get_device_info_by_index 方法来获取设备信息,然后通过 get_default_input_device_info 方法来获取系统默认的录音设备。
指定录音设备
PyAudio提供了一个 get_device_count() 方法,可以获取当前系统的录音设备数量,然后通过 get_device_info_by_index() 方法可以获取指定设备的信息。
|
|
以下是我电脑运行结果:
|
|
其中 立体声混音 (Realtek(R) Audio) 是 device 2。即使此时系统默认的录音设备是外录,我们也可以通过指定 `input_device_index = 2 进行内录。
|
|
如何同时内录和外录
我们可以使用 2 个单独的线程将 2 个不同的录音设备(声音输入源)记录到单独的 Wav 文件中。然后使用 pydub 库混合这两个文件。
|
|
