⏰ 事件关键时间轴
| 日期 | 事件 | 主要涉及方 |
|---|---|---|
| 6月30日 | 华为开源盘古Pro MoE模型 | 华为 |
| 7月3日 | HonestAGI发布报告,质疑抄袭 | HonestAGI、开发者社区 |
| 7月5日 | 华为官方回应否认抄袭 | 华为诺亚方舟实验室 |
| 7月6日 | 内部员工爆料存在套壳行为 | 匿名爆料者 |
| 7月7日 | 行业深度分析,阿里沉默,报告下线 | 媒体、社区 |
| 7月8日 | GitHub 持续爆料华为盘古大模型开发乱象 | 媒体、社区 |
华为开源盘古Pro MoE模型
2025年6月30日,华为正式开源 盘古Pro MoE 720亿参数混合专家模型(MoE架构)及70亿参数稠密模型,宣称其为“基于昇腾硬件平台自研训练”,旨在推动昇腾AI生态建设147。
GitHub用户@HonestAGI 发布技术报告
7月3日,自称哥斯达黎加大学的韩国研究者,通过 “LLM-Fingerprint”技术(提取Transformer层注意力参数标准差生成“指纹”)分析发现:
- 盘古Pro MoE与阿里通义千问 Qwen-2.5 14B的注意力参数相似度高达0.927(1为完全一致),远超行业正常阈值(通常≤0.7)。
- 在盘古开源代码中发现 阿里版权声明(“Copyright 2024 The Qwen team, Alibaba Group”)。
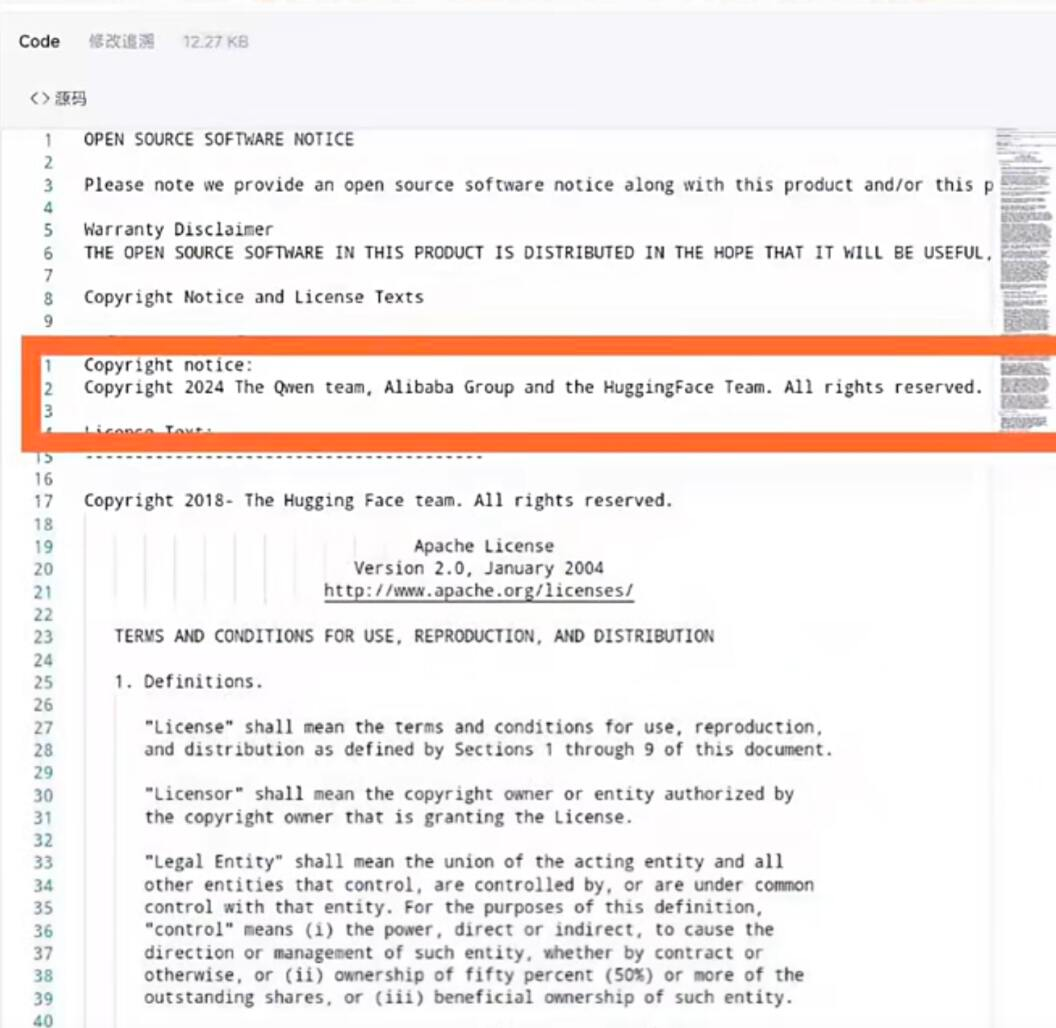
- 报告推断盘古可能通过 “增量训练+架构调整”复用Qwen模型权重,非独立训练。
报告迅速发酵:引发开发者社区热议,质疑华为技术原创性。
华为官方首次回应
2025年7月5日,华为诺亚方舟实验室发布声明:
我们注意到近期开源社区及网络平台关于盘古大模型开源代码的讨论。
盘古 Pro MoE 开源模型是基于昇腾硬件平台开发、训练的基础大模型,并非基于其他厂商模型增量训练而来,在架构设计、技术特性等方面做了关键创新,是全球首个面向昇腾硬件平台设计的同规格混合专家模型,创新性地提出了分组混合专家模型(MoGE)架构,有效解决了大规模分布式训练的负载均衡难题,提升训练效率。其他技术特性创新,请参考昇腾生态竞争力系列技术报告披露内容。
盘古 Pro MoE 开源模型部分基础组件的代码实现参考了业界开源实践,涉及其他开源大模型的部分开源代码。我们严格遵循开源许可证的要求,在开源代码文件中清晰标注开源代码的版权声明。这不仅是开源社区的通行做法,也符合业界倡导的开源协作精神。我们始终坚持开放创新,尊重第三方知识产权,同时提倡包容、公平、开放、团结和可持续的开源理念。
简单概括如下:
- 否认抄袭:强调盘古为 “昇腾硬件平台独立开发训练” ,非基于其他模型增量训练。
- 承认 “部分基础组件参考开源实践” (含Qwen代码),但称已严格遵循开源协议标注版权。
- 突出 “分组混合专家模型(MoGE)”架构创新,称其解决分布式训练负载均衡问题。
社区争议未平息:
- 质疑方认为华为未解释高相似度参数成因,且拒绝公开训练日志、数据集等关键证据。
盘古之殇
HW-whistleblower/True-Story-of-Pangu: 诺亚盘古大模型研发背后的真正的心酸与黑暗的故事。
2025年7月6日,自称为吹哨人的华为诺亚方舟实验室员工匿名爆料,发表文章《盘古之殇:诺亚盘古大模型研发背后的真正的心酸与黑暗的故事》,揭露盘古大模型研发过程中存在的技术造假、管理腐败及人才流失问题。指控核心团队(四纵)长期被小模型实验室(十六纵)窃取成果,高层纵容套壳竞品模型的行为,导致原创团队士气崩溃。

自称盘古团队成员者爆料:
- 因算力不足,团队曾 套壳Qwen 1.5 110B进行续训,并通过 “加层、扩参数、洗水印” 伪装原创;领导默许此类行为。
- 指控盘古Pro MoE实为 Qwen的改造版本(如参数从110B扩至135B)。
技术社区持续辩论:
- 支持者认为指纹技术“不科学”,相似度高或因类似架构/训练目标。
- 反对者要求华为开放模型API或权重,以多维度验证(如梯度/激活分析),但华为未响应。
行业反思与影响扩散
- 媒体深度分析事件影响:
- 揭露AI开源模糊地带:模型权重复用、增量训练与微调的边界不清,缺乏法律与伦理标准。
- 回溯华为历史争议:思科路由器代码纠纷(2023)、鸿蒙“套壳安卓”质疑(2021)等,质疑其“技术自研”人设。
- 阿里保持沉默:通义千问团队未公开回应。
💡 最新进展(截至2025年7月8日)
- GitHub报告下线:@HonestAGI删除原始分析库,称将完善论文提交学术会议(如ICLR)。
- 华为未追加回应:维持“合规使用开源代码”立场,未回应内部爆料。
- 行业呼吁标准化:多专家建议建立 AI开源合规指引与 模型相似性评估框架,避免“套壳炒作”。
Github 持续爆料华为盘古大模型开发乱象
大家在吹哨人的Github issues 区持续爆料华为盘古大模型开发乱象,揭露更多细节和证据。现在已经有270个open issues。
Issues · HW-whistleblower/True-Story-of-Pangu
knemik97/Manifesto-against-the-Plagiarist-Yunhe-Wang: 讨贼王云鹤檄文
在此事件中,有一个人物浮出水面,他就是华为诺亚方舟实验室的王云鹤(Yunhe Wang)。
王云鹤,1991年生于黑龙江。2018年博士毕业进入华为,经历不到7年时间,于2025年2月中旬,从小模型实验室主任任上,正式顶替姚骏,被任命为诺亚方舟实验室主任(这一位置的前任包括大家耳熟能详的杨强、李航等,王云鹤可谓德不配位),摇身一变成为了原本对手团队的直接领导,为其直接“抢果子”而非“赛马”提供了直接方便。
身在华为,王云鹤今天造假的是718B,明天就可能是大国重器上的通信计算设备,无人机的控制系统,作战通信终端的核心元件。。。
因此,王云鹤及其小模型实验室团队,其剽窃套壳行为必须受到审判。其小模型实验室中所有不学无术、只想摘果子的成员,势必要被钉在中国大模型发展的耻辱柱上,遗臭万年。
💎 事件本质与警示
华为盘古事件暴露了中国AI产业在创新压力下的三重困境:
- 技术诚信vs商业利益:算力成本高企催生“套壳捷径”,但掩盖技术来源损害行业信任基石。
- 管理文化溃堤:“唯KPI论”导致逆淘汰,实干者流失削弱长期竞争力。
- 国产化叙事危机:“全栈自研”口号与实操背离,动摇昇腾生态信心。
相信盘古大模型也可以复制DeepSeek的成功经验,只是目前而言只是被某些别有用心的做坏了。若投机者持续碾压实干者,中国AI的瓶颈将非英伟达断供,而是内斗不息。
参考资料
- 华为盘古大模型员工自曝:存在套壳、续训、洗水印!_苏州_dense_训练
- 华为人工智能大模型盘古,疑似抄袭阿里Qwen|大瓜|相似性|阿里qwen|深度思考模型_网易订阅
- HW-whistleblower/True-Story-of-Pangu: 诺亚盘古大模型研发背后的真正的心酸与黑暗的故事。
- 华为盘古大模型“抄袭”阿里Qwen?官方回应_@HonestAGI_Pangu_团队
- 华为盘古团队回应AI模型抄袭争议:严格遵循开源许可- DoNews
- 韩国大学生质疑盘古大模型套壳抄袭,华为回应已严格遵循开源许可-CSDN博客
- 关于抄袭,华为最新回应
- 盘古大模型出现通义千问代码,否认抄袭却恐难服众!_财富号_东方财富网
- 华为团队回应盘古开源AI模型抄袭争议:并非基于其他模型增量训练,已严格遵循开源许可-钛媒体官方网站
- 华为盘古团队回应开源代码争议,称严格遵循开源要求,回应了哪些争议?还有哪些问题待厘清? - 知乎
- 华为盘古开源大模型被指抄袭Qwen2.5大模型,HonestAGI的这份技术报告怎么理解? - 知乎
- 华为盘古大模型被指出抄袭阿里 Qwen 大模型,是怎么回事? - 知乎
- GitHub 持续爆料华为盘古大模型开发乱象,华为诺亚方舟实验室到底出了什么问题? - 知乎
