前段时间,利用 Ollama 为 字幕翻译 - 字幕工具箱 新增加了本地的翻译模型 TranslateGemma。
我觉得这种暴露本地服务API的方式还挺有意思的,大有可为。
硬字幕提取
视频与字幕的结合一般有三种方式:硬字幕和软字幕、外挂字幕。
- 硬字幕:又叫内嵌字幕。字幕被直接嵌入到视频文件中,无法更改或删除。
- 软字幕:又叫内挂字幕、封装字幕、内封字幕。加字幕的过程叫做封装。视频一般为mkv格式。
- 外挂字幕:字幕文件与视频文件分开存储,播放时需要用户手动加载字幕文件(如字幕文件与视频文件相同命名,播放器会自动加载)。字幕一般为srt、ass、ssa等格式。
硬字幕(Hard-coded Subtitles)是永久嵌入视频画面中的文本,属于视频文件的一部分,不可关闭或轻易修改。其版权遵循著作权法:若为原创翻译,字幕创作者享有翻译权;若未经授权对有版权影视剧加硬字幕并传播,则构成侵权。
传统硬字幕提取工具的问题
我自己推荐过好几个或几种硬字幕提取方式,如:
- 望言OCR 下载
- Video Subtitle Extractor 下载
- Video Sub Finder 下载
- 硬字幕提取神器:Video Subtitle Extractor_哔哩哔哩
- 【免费开源轻量稳定】硬字幕提取最佳方案:VideoSubFinder + Umi-OCR_哔哩哔哩
- 字幕提取快准稳!望言智能OCR支持100+视频批量处理_哔哩哔哩
这类工具往往安装困难、操作复杂、设备要求高,效果差强人意。
做为字幕工具箱的作者,我一直想做一款轻量好用的硬字幕提取工具。
开源AI OCR 模型
现在基于AI的OCR工具越来越好用,比如:
ollama 自然也集成了以上模型。
-
MedAIBase/PaddleOCR-VL
ollama run MedAIBase/PaddleOCR-VL:0.9b -
glm-ocr
ollama run glm-ocr -
deepseek-ocr
ollama run deepseek-ocr -
maternion/LightOnOCR-2
ollama run maternion/LightOnOCR-2
实测这几个模型的效果都不错,尤其是 GLM OCR,识别准确率高,速度快,支持多语言,适合做硬字幕提取。
模型越小,速度越快,适合实时提取;模型越大,准确率越高,适合批量处理。
SubOCR 史上最轻量硬字幕提取工具
实现这个工具也非常的简单,一个本地网页脚本足以。
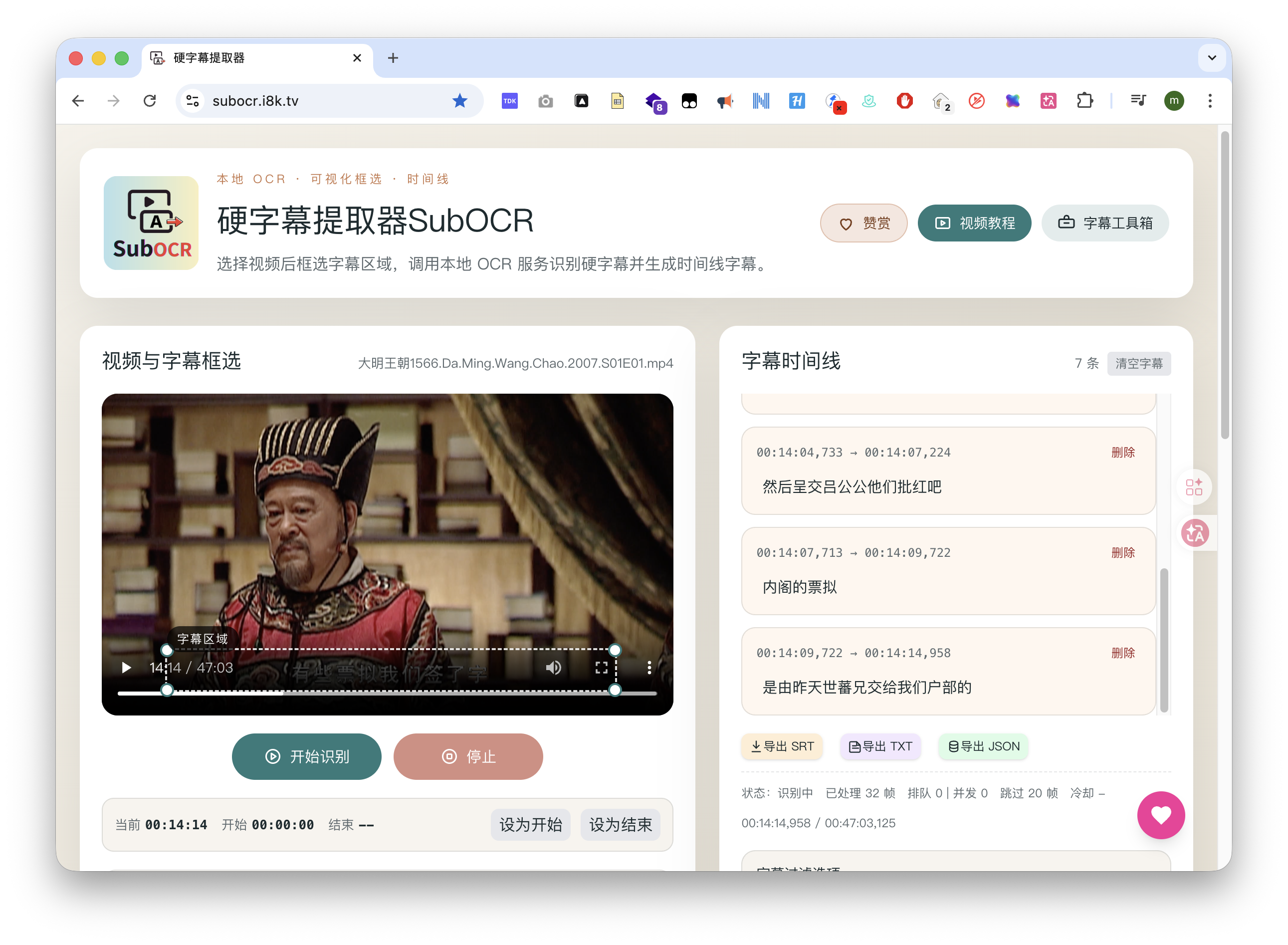
原理简述
- 读取本地视频,按固定间隔截图指定字幕区域(可拖拽裁剪框),生成帧图像。
- 将帧图像送到 OCR 服务(通用接口或 Ollama),解析返回文本并做清洗过滤。
- 按时间顺序合并相近文本,形成字幕段落(起止时间+文本),并实时展示。
- 支持导出为 SRT/TXT/JSON 文件。
注意事项
- 需要先安装并运行 Ollama 服务,确保本地可以访问 Ollama 模型。
- 你不能把发送请求的操作写在服务端代码里,因为 Ollama 的服务是运行在你本地的机器上的,服务器是无法访问你本地的服务的。
- OCR 服务必须可被浏览器访问(CORS/网络连通);超时与并发需根据服务能力调整。
- 裁剪区域要覆盖字幕位置,否则识别空白或误识别。
- 结果清洗会过滤提示词回显、标点/空白等噪声,必要时可调整过滤规则。
- 识别频率过高会导致服务拥塞或失败,应合理设置间隔、并发和回退时间。
- 导出前建议检查列表中是否有误识别或缺失段落,必要时手动编辑。
Ollama 跨域设置
- 开启
Expose Ollama to the network选项:
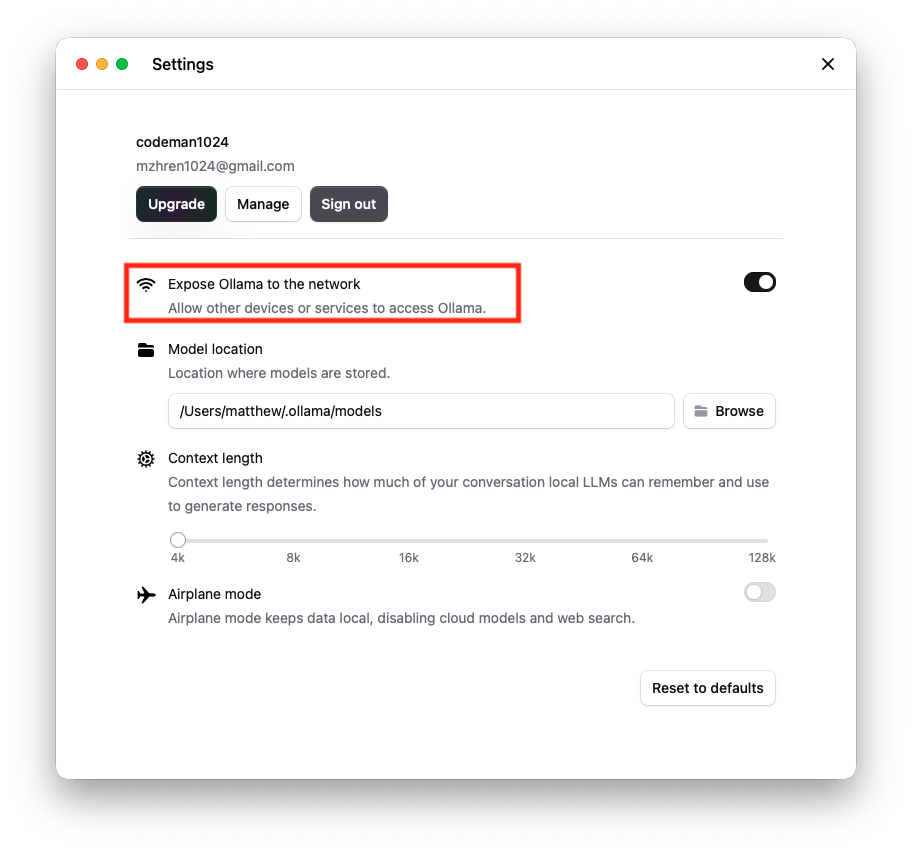
- 设置跨域请求环境变量:
由于 Ollama 的默认参数配置,启动时设置了仅本地访问,所以跨域访问以及端口监听需要进行额外的环境变量设置 OLLAMA_ORIGINS。
在在 macos 或 Linux 系统中,使用 launchctl 设置环境变量:
|
|
也可以指定具体的域名:
|
|
在 Windows 系统中,可以通过环境变量设置窗口进行设置:
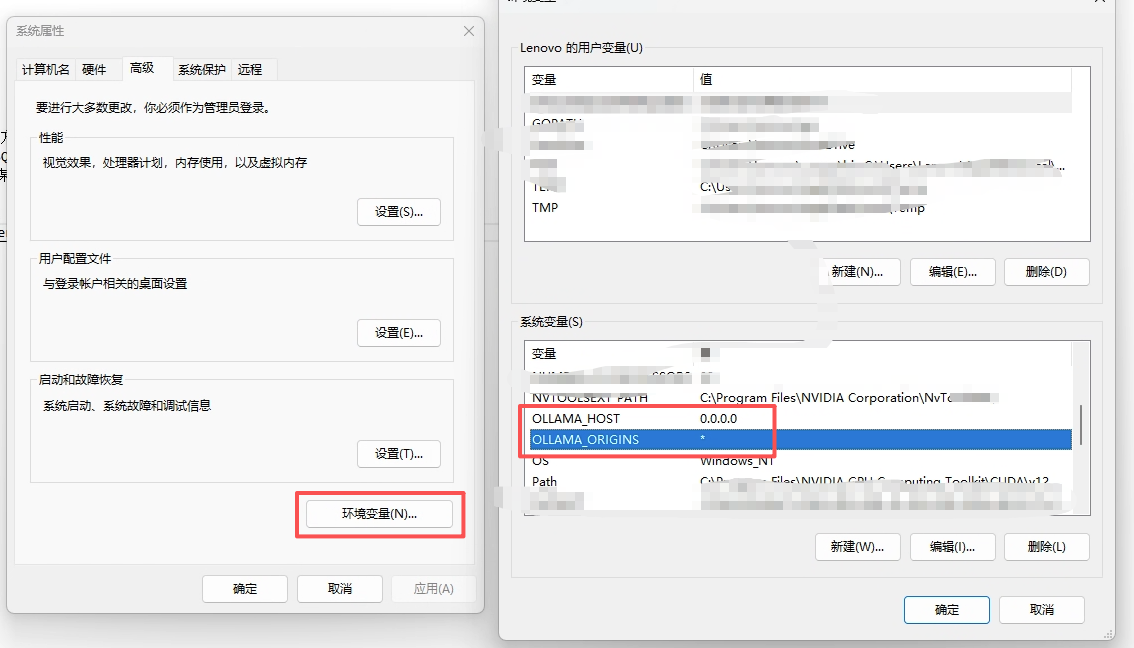
配置完成后,重启 Ollama 服务即可。(重要‼️)
Ollama 内存常驻
Ollama Keep Alive 是 Ollama 用于控制大模型在内存或显存中驻留时间的服务器环境变量。通过设置该变量(如 5m、1h 或 -1),用户可以决定模型在最后一次交互后保留多长时间,以减少重复加载带来的延迟。默认通常为 5 分钟。
主要功能与设置方法:
- 功能: 防止模型频繁加载/卸载,从而优化下一次请求的响应速度。
- 设置方式:
- 环境变量(全局): 在启动 Ollama 服务时设置
OLLAMA_KEEP_ALIVE=10m。 - API 参数(单次): 在
/api/generate或/api/chat中指定keep_alive参数,覆盖全局设置。
- 环境变量(全局): 在启动 Ollama 服务时设置
- 参数值:
10m: 保持 10 分钟。1h: 保持 1 小时。0: 立即卸载。-1: 永久驻留内存。
常见场景:
如果显存充足,可以通过 OLLAMA_KEEP_ALIVE=-1 让模型始终常驻,实现即时响应。如果显存不足,可以将其设置为较短时间(如 1m)以便快速释放资源。
