Ollama 想必大家都很熟悉了,几乎每个本地部署大模型的视频教程都会提到它。Ollama 使用也非常的简单,也没啥技巧可言。这里记录我在使用过程中遇到的一些问题和解决方法,顺便夹带点私货。
Ollama
什么是 Ollama ?正如 Ollama 官方仓库所说:本地启动并运行大型语言模型。
Ollama 是一个开源的大型语言模型服务工具,旨在帮助用户快速在本地运行大模型。通过简单的安装指令,用户可以通过一条命令轻松启动和运行开源的大型语言模型。 它提供了一个简洁易用的命令行界面和服务器,专为构建大型语言模型应用而设计。用户可以轻松下载、运行和管理各种开源 LLM。与传统 LLM 需要复杂配置和强大硬件不同,Ollama 能够让用户在消费级的 PC 上体验 LLM 的强大功能。
常用命令
运行 ollama help 可以查看所有命令的帮助信息。
| 命令 | 描述 |
|---|---|
| ollama serve | 启动 Ollama |
| ollama create | 从 Modelfile 创建模型 |
| ollama show | 显示模型信息 |
| ollama run | 运行模型 |
| ollama stop | 停止正在运行的模型 |
| ollama pull | 从注册表中拉取模型 |
| ollama push | 将模型推送到注册表 |
| ollama list | 列出所有模型 |
| ollama ps | 列出正在运行的模型 |
| ollama cp | 复制模型 |
| ollama rm | 删除模型 |
| ollama help | 显示任意命令的帮助信息 |
安装大模型
运行 ollama run 命令时,如果没有安装大模型,会自动下载并安装。如果想提前下载大模型,可以使用 ollama pull 命令。
大模型文件较大,下载时间较长。如果下载中断,下次再次运行 ollama run 时,会继续下载。
如果不想通过 run 命令下载模型,可以单独下载 GGUF 模型文件,然后通过 ollama create 命令创建模型。
GGUF(GGML Universal File)是一种专为大型语言模型(LLM)设计的文件格式。它旨在解决大型模型在实际应用中遇到的存储效率、加载速度、兼容性和扩展性等问题,从而简化 LLM 的使用和部署。
GGUF 文件可在 Models - Hugging Face 下载。
注意事项
Ollama 服务启动后,会占用大量内存。如果内存不足,会导致系统卡顿,甚至崩溃。建议在空闲内存较大、大显存的机器上运行。
大模型文件较大,如果你下载的模型跑不起来(强扭的瓜不甜),记住一定要调用 ollama rm 命令删除模型,这样可以节省磁盘空间。
Windows下,ollama 默认会在C盘下创建一个 .ollama 文件夹,存放模型文件。如果你的C盘空间不足,可以通过设置环境变量 OLLAMA_MODELS 来更改模型文件存放路径。如:
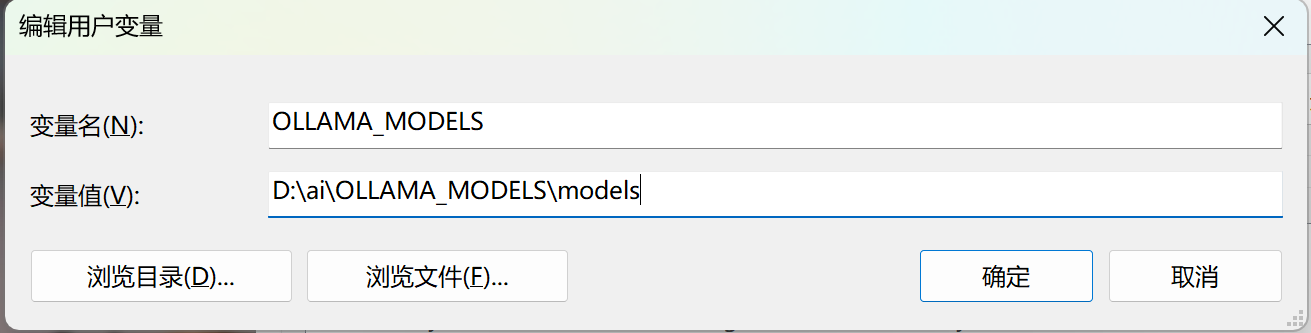
之后下载的模型文件会存放在指定路径下。
注意:设置环境变量后,需要重启终端才能生效。
之后,模型文件会存放在指定路径下。
–verbose 参数
ollama run 命令默认不会输出详细信息,如果想查看详细信息,可以使用 --verbose 参数。如:
|
|
大模型回答完问题后,会输出详细统计信息。
|
|
这个统计指标分别是:
- total duration 总持续时间:从开始到结束的总时间。
- load duration 模型加载时间:加载模型所需的时间。
- prompt eval count 提示词消耗令牌数:处理提示词所消耗的令牌数。
- prompt eval duration 处理提示词花费时间:处理提示词所花费的时间。
- prompt eval rate 处理提示词效率:处理提示词的效率。
- eval count: 实际生成的输出令牌数:生成回复所需的令牌数。
- eval duration 生成回复所需的时间:生成回复所需的时间。
- eval rate 生成回复的效率:生成回复的效率。
因为我是在终端中运行的,所以它会输出一个终端表格。为了解析这个终端表格,(找了一圈没找到相关的小工具)于是我用AI写了个小工具,可以将这个表格转换成 Markdown 表格。