DeepSeek是真的开源吗?大模型开源与传统软件开源的区别
DeepSeek 不仅开源了模型,第一时间公开了训练方法.
上周五,DeepSeek 宣称,将在下周连续开源5个项目库。
果不其然,本周一,DeepSeek 开源了生产环境的加速工具:FlashMLA。

Day 1 : FlashMLA
项目地址:https://github.com/deepseek-ai/FlashMLA
FlashMLA 是用C++编写的,针对底层CUDA的优化工具。DeepSeek用了该加速工具之后,阉割版H800的内存带宽接近了H100了。
Achieving up to 3000 GB/s in memory-bound configuration and 580 TFLOPS in computation-bound configuration on H800 SXM5, using CUDA 12.8.
在内存受限的配置下,基于CUDA 12.8,FlashMLA 在 H800 SXM5 上实现高达 3000 GB/s的带宽,而在计算受限的配置下,FlashMLA 的计算性能达到了 580 TFLOPS。
H100 vs H800
H100 和 H800 都是英伟达的GPU,但它们之间有一些关键的区别。 H100是英伟达的旗舰级产品,具有更高的核心数和更快的内存速度,适用于处理大规模计算任务。 H800则是英伟达的中端产品,性能较低,但价格更加亲民,适用于中低端计算任务。
MLA(Multi-Head Latent Attention)多头潜在注意力
DeepSeek 采用了多头潜在注意力(MLA)机制。假设你需要阅读一本百科全书,MLA机制就像是很多个有不同特长的“小助手”,默默的一起帮你阅读。它们分工配合,当读到关于动物的章节时,关注动物图片的小助手,就会更认真的去看相关的图片。关注文字的小助手,会重点看描述动物特征和习性的文字。最后,将多个小助手关注的信息,汇总起来。这样,你就能快速有效的了解这本百科全书。
Day 1 - DeepSeek开源周第一天:FlashMLA框架开源_哔哩哔哩_bilibili
Day 2 : DeepEP
deepseek-ai/DeepEP: DeepEP: an efficient expert-parallel communication library
项目地址:https://github.com/deepseek-ai/DeepEP
首个面向MoE(混合专家)模型的开源通信库,支持全对全通信模式与FP8低精度运算调度,通过优化节点间NVLink/RDMA网络传输效率,实现MoE模型训练推理的通信效率飞跃。
我们用城市交通做类比。假设城市中的一个个地点,就是一个个计算节点。道路上的汽车就是一个又一个数据。在一座繁华喧闹的城市中,如果没有精心的道路跟完善的交通规则,拥堵和延迟不可避免。DeepEP就像是一套先进的交通系统,旨在最大化效率,确保数据传输的高效性和稳定性。并且,不同于别的计算任务,大模型的训练和推理,尤其需要巨量的数据,在海量的计算节点中来回传输。90%的情况下,数据传输的效率,就是系统的性能瓶颈。DeepEP就是为了解决这个问题而生。
DeepSeek MoE
Transformer的普及让人们误认为提升AI能力就是需要不断的堆设备,堆模型数。这对算力、数据、稳定性都提出了更高的要求,而且推理成本也会居高不下,跑万亿个参数的计算才能算出一个token的速度和成本比较不可观。所以,将若干个模型堆成一个MoE大模型似乎是个必然趋势。
MOE,全称Mixture of Experts,也就是混合专家模型,它的设计理念十分巧妙,就像是组建了一个超级 “专家团队” 。在MOE架构中,有多个不同的专家网络,每个专家都有自己的 “专长领域”,专门负责处理特定类型的任务或数据。比如在处理自然语言时,有的专家擅长理解语法结构,有的则对语义理解更在行。MLA就是在该框架下的技术创新。
DeepSeek重磅开源DeepEP,大模型训练&推理效率暴涨!粉碎算力垄断,重塑MoE模型训练新范式!_哔哩哔哩_bilibili
Day 3 : DeepGEMM
deepseek-ai/DeepGEMM: DeepGEMM: clean and efficient FP8 GEMM kernels with fine-grained scaling
项目地址:https://github.com/deepseek-ai/DeepGEMM
矩阵乘法加速库DeepGEMM,采用细粒度scaling技术,在Hopper GPU上实现1350+ FP8 TFLOPS性能,支持密集布局和MoE分组矩阵运算,显著提升大模型训练效率。

Day 4 : DualPipe
项目地址:https://github.com/deepseek-ai/DualPipe
双向流水线并行算法,通过计算与通信阶段的重叠,将跨节点通信开销降至近乎为零,减少GPU闲置时间;
双向流水线流程
与传统的受气泡开销影响的流水线并行不同,DualPipe 实现了前向和后向计算-通信阶段的同时进行:
- •前向和后向阶段之间的完全同步
- •通过双通道处理消除流水线气泡
- •优化所有可用设备的资源利用率
- •通过高效的梯度处理减少内存占用
- •基于计算需求的自适应调度

专家并行负载均衡器 (EPLB)
deepseek-ai/EPLB: Expert Parallelism Load Balancer
在使用专家并行(EP)时,不同的专家会被分配到不同的 GPU 上。由于不同专家的负载可能会根据当前工作负载而变化,因此保持不同 GPU 的负载均衡非常重要。正如 DeepSeek-V3 论文中所述,我们采用了冗余专家策略,即对负载较重的专家进行复制。然后,我们通过启发式方法将复制的专家分配到 GPU 上,以确保不同 GPU 之间的负载均衡。此外,得益于 DeepSeek-V3 中使用的组限专家路由机制,我们还尽可能将同一组的专家放置在同一节点上,以减少节点间的数据流量。
为了便于复现和部署,我们在 eplb.py 中开源了我们部署的 EP 负载均衡算法。该算法基于预估的专家负载计算出一个均衡的专家复制和分配计划。需要注意的是,预测专家负载的具体方法不在本代码库的范围内。常见的方法是使用历史统计数据的移动平均值。
Profiling Data
deepseek-ai/profile-data: Analyze computation-communication overlap in V3/R1.
Profile-Data 提供训练与推理阶段的性能可视化工具,帮助开发者精准定位瓶颈,实现端到端优化。
Day 5 : 3FS文件系统 & Smallpond
3FS
项目地址:https://github.com/deepseek-ai/3FS
3FS:基于SSD和RDMA网络的并行文件系统,实现180节点集群6.6TiB/s读取吞吐量,单节点KVCache查找峰值超40GiB/s,支持强一致性语义的分布式存储架构;
3FS是目前全球唯一大模型分布式文件管理系统,6TiB/s巨量吞吐性能,开辟训练新篇章!
Smallpond
deepseek-ai/smallpond: A lightweight data processing framework built on DuckDB and 3FS.
项目地址:https://github.com/deepseek-ai/smallpond
Smallpond:轻量级数据处理框架,结合DuckDB实现PB级数据管理,覆盖训练数据预处理、检查点保存、向量搜索等全场景。
Day 6 : DeepSeek-V3/R1推理系统概述
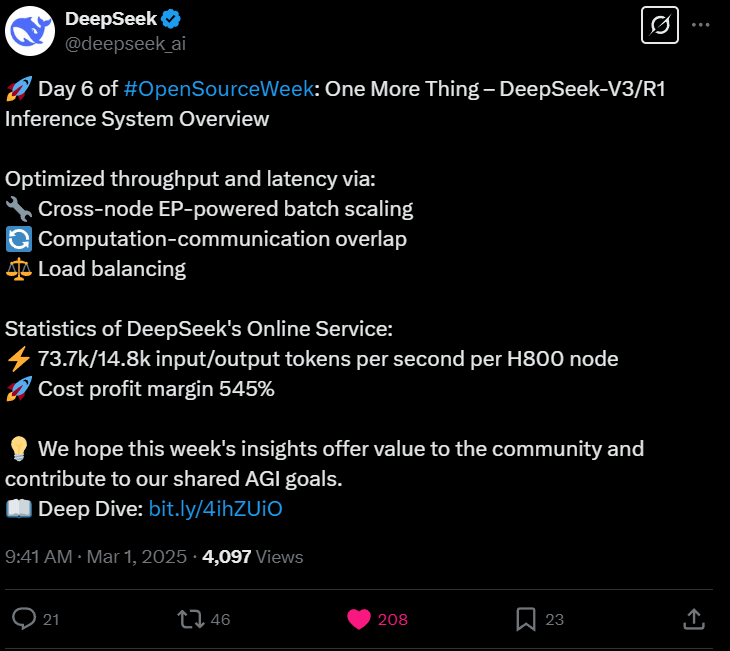
开源周的第六天:还有一件事——DeepSeek-V3/R1推理系统概述
通过以下方式优化吞吐量和延迟:
- 跨节点EP驱动的批量扩展
- 计算-通信重叠
- 负载均衡
DeepSeek在线服务的统计数据:
- 每个H800节点每秒输入/输出73.7k/14.8k个令牌
- 成本利润率545%
DeepSeek 开源周总结
此次DeepSeek开源周,6天疯狂开源8个大模型基建项目,覆盖AI训练、推理、并行计算等多个关键领域。被评价为“用软件重新定义算力”,通过算法优化充分榨取硬件性能,在未升级硬件条件下实现训练效率跃升。对比同期OpenAI发布的GPT-4.5(运行成本达DeepSeek-R1的270倍),DeepSeek技术路线展现出显著的性价比优势。
